Microsoft’s NEW Multimodal AI CoDi — Is Taking The Tech Space By Storm
Microsoft’s NEW Multimodal AI CoDi

Software Engineer with more than 10 years of experience in Software Development. I have a knowledge of several programming languages and a Full Stack profile building custom software (with a strong background in Frontend techniques & technologies) for different industries and clients; and lately a deep interest in Data Science, Machine Learning & AI. Experienced in leading small teams and as a sole contributor. Joints easily to production processes and is very collaborative in working in multidisciplinary teams.
Incredibly, Microsoft’s iCode project has Unvelle CoDi, a composable diffusion-based artificial intelligence model that can both interact with and generate multi-modal content.
But there’s a twist. Amazingly, this diffusion model is capable of simultaneously processing and generating content across multiple modalities, including text, images, video, and audio, plus it significantly departs from traditional generative AI systems, which are typically limited to specific input modalities.
What can this thing do?
Firstly, it’s important to understand that CoDi represents a solution to the limitations of traditional single-modality AI models, which often involve a cumbersome and slow process of combining modality-specific generative models.

But CoDi employs a unique, composable generation strategy that bridges alignment in the diffusion process, facilitating synchronized generation of intertwined modalities, such as temporary aligned video and audio. This approach allows CoDi to condition on any combination of inputs and generate any set of modalities, even though it’s not present in the training data. Secondly, the training process of CoDi is also distinctive and innovative.
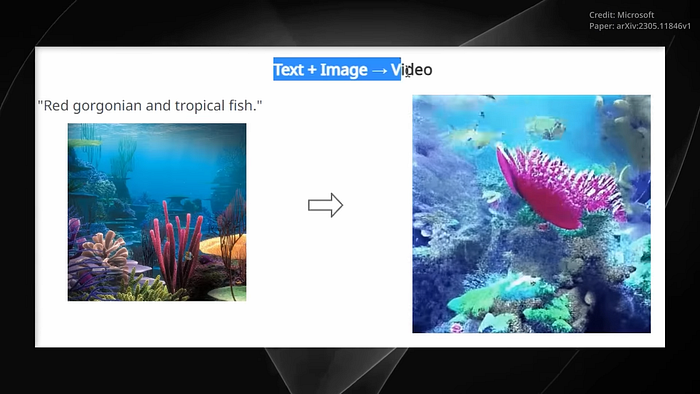
It involves projecting input modalities, such as images, video, audio, and language into a common semantic space, allowing for flexible processing of multi-modal inputs, plus a cross-attention module and an environment encoder. CoDi is capable of generating any combination of output modalities simultaneously.
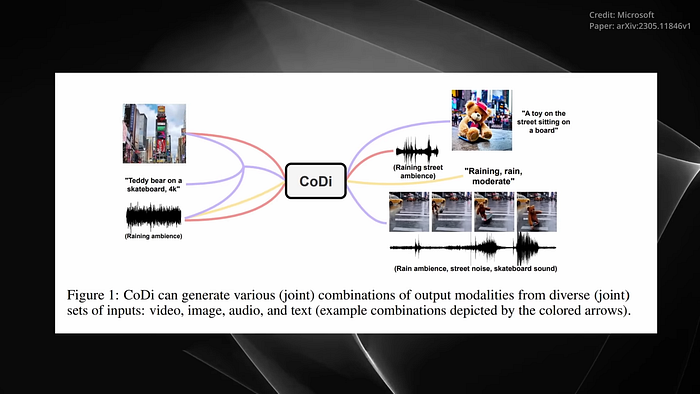
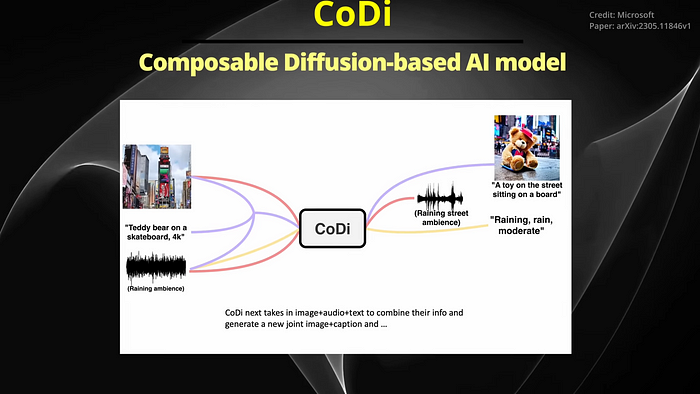
This unique approach to training is a response to the scarcity of training data sets for most of today’s modality combinations. Impressively, the researchers demonstrated CoDis capabilities in one instance. CoDi was given the text prompt, Teddy Bear on Skateboard, 4K, High Resolution, an image of Times Square and the Sound of Rain. From these disparate inputs, CoDi generated a short video of a Teddy Bear skateboarding in the rain at Times Square, accompanied by the synchronized sounds of rain and street noise.
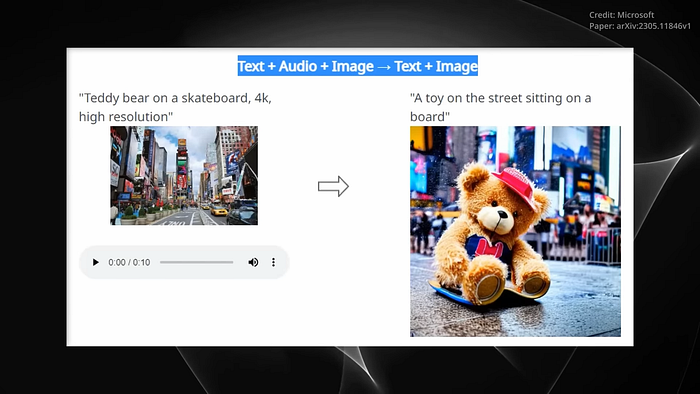
This example showcases CoDi’s ability to generate synchronized video and audio from separate text, audio, and image prompts. Indeed, the potential applications of CoDi are vast and varied, with this technology having the potential to revolutionize the way L.I. interacts with and generates content across a variety of fields. Most exciting is what this multimodal A.I. model promises, which is to bring about a new era of media experience. This innovative technology, capable of processing and generating content across multiple modalities, is poised to redefine the way we consume and interact with media.
But what does this mean for the future?
Number 1:
Personalized Content Creation CoDi’s ability to process and generate content across text, images, video, and audio could lead to a new level of personalized content. Media platforms could leverage this technology to create tailored content that caters to individual user preferences, enhancing user engagement and satisfaction.
Number 2:
Immersive Multimedia Experiences CoDi’s capability to synchronize the generation of intertwined modalities, such as video and audio, opens up possibilities for more immersive multimedia. This could transform the way we consume entertainment, from interactive movies and video games to virtual reality experiences.
Number 3:
Automated Content Generation With CoDi, media companies could automate the generation of content across different modalities. This could streamline the content creation process, allowing for faster production and distribution of news, articles, videos, and more.
Number 4:
Accessibility CoDi could significantly enhance accessibility in media. For instance, it could generate audio descriptions for videos for people with visual impairments, or create sign language interpretations for audio content for those with hearing impairments.
Number 5:
Interactive Learning Materials In the field of educational media, CoDi could be used to create engaging and interactive learning. By processing and generating content across multiple modalities, it could cater to different learning styles, making education more inclusive and effective. All in all, as CoDi continues to evolve, we can look forward to a future where media is not just consumed, but interacted with, in a way that is more engaging and inclusive than ever before.

But CoDi isn’t the only AI breakthrough that Microsoft is unveiling, as it also just released its new Cosmos 2 model, catapulting the sphere of multi-modal large language models to previously unattained heights, with Cosmos 2’s remarkable functionality transcending conventional textual interactions, expanding into the domain of image analysis and interpretation to push the envelope of what’s possible. Furthermore, Cosmos 2 is more than an academic research concept. It’s a fully operational product with the remarkable ability to process user-submitted images and produce insightful responses. It demonstrates a monumental leap forward in AI-facilitated image recognition, showcasing Microsoft’s ingenuity and forward-thinking approach in the development of multi-modal large language models.

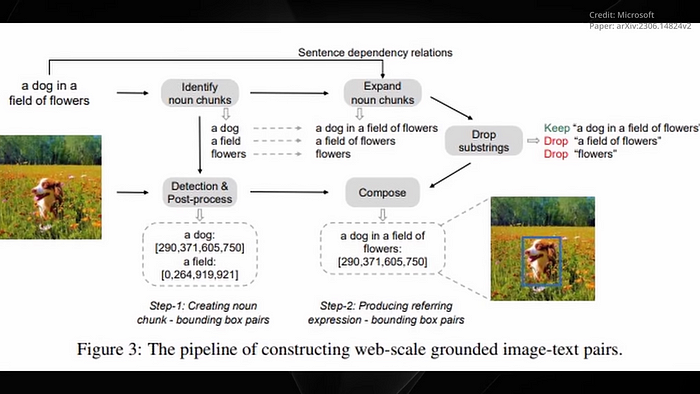
A distinguishing feature of Cosmos 2 lies in its use of bounding boxes, a technique employed to identify and label objects in images. Through this approach, Cosmos 2 analyzes images, pinpoints the objects within, and then leverages bounding boxes to demarcate each object’s location. To illustrate, consider three images each containing different objects, an emoji, two cows in a dense forest, and a street sign reading Welcome to Carnaby Street. Prompted to locate the left eye of the emoji, count the number of cows, and read the street sign respectively, Cosmos 2 responded by drawing a bounding box around the requested objects, exhibiting its impressive ability to accurately identify, locate, and enumerate objects and decode texts within an image. Upon deeper examination of Cosmos 2’s capabilities, it is clear that the model’s ability to interpret images transcends rudimentary image recognition.

When shown an anomalous image of a turtle racing a rabbit, Cosmos 2 identified the scene as unique, recognizing the unusual sight of a slow-moving turtle outpacing a rabbit. When presented with an image of a boy attached to a boat, the AI model accurately pinpointed the boy and grasped the context depicted in the image. Further showcasing its nuanced analytical capability, when Cosmos 2 was tasked with identifying the primary difference between two similar-looking bottles bearing different labels, it correctly identified that the distinguishing feature was indeed the labels.
Impressively, when asked to provide a detailed description of an image, Cosmos 2 rose to the challenge. Given an image of a snowman sitting by a campfire, presumably enjoying a hot meal, Cosmos 2 offered a vivid comprehensive description that included not only the snowman and the campfire but also captured the tranquil ambience of the scene. In Cosmos 2’s technical overview, the model’s method of breaking down images into parts, independently identifying each part, and then assembling these elements into a unified description is highlighted. This unique strategy guarantees that Cosmos 2 can accurately recognize and identify multiple aspects within a single image.
Comparative analysis of Cosmos 2 with benchmark models like visual-bit, Kip, Vilbert, and GPT4 suggests a key advantage, Cosmos 2 excels in zero-shot capabilities. This means the model is a depth at undertaking tasks without any specific training or examples about that task, leveraging its general knowledge or pre-trained abilities to generate outputs for novel tasks.
In addition to its image analysis prowess, Cosmos 2 also shines in text recognition. Its capabilities align with those of chat GPT in recognizing and predicting text, distinguishing it as more than just an image classifier.
However, Cosmos 2 like any AI model is not without its limitations. Occasionally, the model might misidentify elements, such as mistaking a man’s left arm for a dog in a black-and-white image or misconstruing the sign for a bench. Nonetheless, these minor oversights do not overshadow Cosmos 2’s trailblazing capabilities. Its innovative ability to comprehend and interpret images marks an exciting step towards a future where AI can interact with the world in deeper, more significant ways. As Cosmos 2 continues to evolve and refine, it promises to set the stage for more comprehensive AI models, thereby transforming the artificial intelligence landscape.
If you enjoyed this blog and want to help it reach a broader audience, please click the like button. I’d also love to hear your thoughts on this tool. So feel free to share your opinions in the comment section.
Thank you so much for listening and stay blessed.




